DEPARTMENT OF POLITICAL SCIENCE
AND
INTERNATIONAL AFFAIRS
Posc/Uapp 815
REGRESSION ANALYSIS

- AGENDA:
- Correlation coefficient
- Two variable regression analysis
- Reading:
- Correlation: Agresti and Finlay, Statistical Methods,
Chapter 9, pages 318
to 323.
- Regression: Agresti and Finlay, Statistical Methods,
Chapter 9, pages 301
to 318
- THE CORRELATION COEFFICIENT:
- A the correlation coefficient, often called Pearson's r or the product-moment
correlation, is perhaps the most commonly cited and used measure of linear
association or correlation in the social and policy sciences.
- Since we'll see a more formal definition in a moment, suffice it to say for now r is
an index that tells how closely a the observations of a bivariate distribution--that is
a simultaneous plot of X and Y as in the plots we have been working with--fall to a
straight lone that does not have a zero slope.
- A simpler way of saying this is that it measures how well a batch of X and
Y data values "fit" a linear function.
- Properties:
- It is a "bounded" measure or index: its value lies between -1.0 and +1.0.
- More formally:

- For perfect positive correlation r = 1.0; for perfect negative
correlation r = - 1.0
- Alternatively one can say that the closer r is to 1.0, where the bars
indicate absolute value, the closer the distribution is to a straight line.
- A value of 0 indicates no linear correlation between X and Y.
- Some pictures illustrate the point.
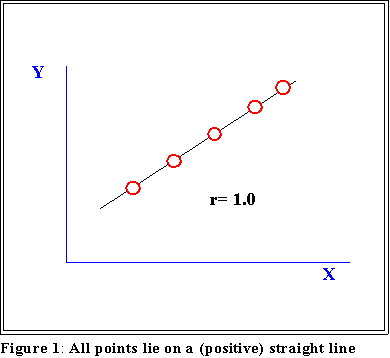
- In the case of perfect positive correlation the value of r is 1.0
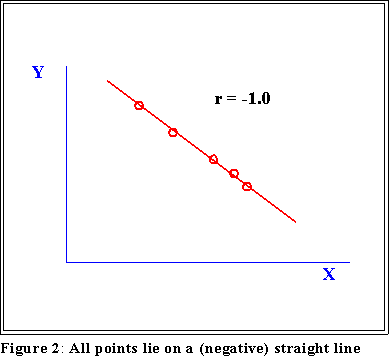
- In the case of perfect negative correlation it is -1.0.
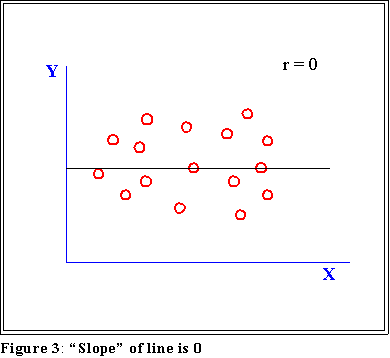
- When there is no linear correlation r is 0.0
- See next page
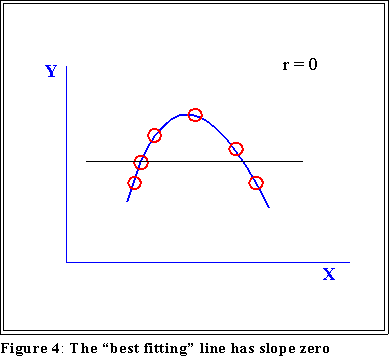
- In this example, the data points are scattered randomly. The best
fitting line has a slope of zero (see below).
- Bur it is possible that r will equal zero even if the two variables, X and Y,
have a "perfect" association, as in this example:
- Most values of r lie between 0 and 1.0 or -1.0. The nearer the maximum
value the "stronger" the linear correlation. For example:
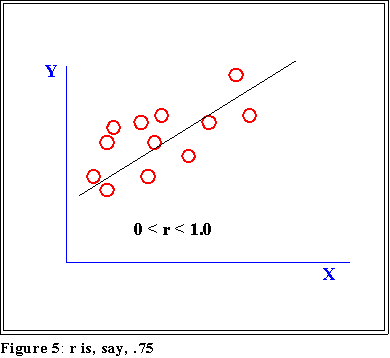
:
- The points do not lie on a straight line, but they come "close" so
the value of r is positive and, in this example, near 1.0, say .75.
- See Agresti and Finlay page 321 for other examples.
- Note also that if the data points slope down from the upper left to the
lower right r will have a negative value.
- The correlation coefficient is a scale free measure: its numerical value does
not depend on the variables unit of measurement.
- So for example, if one is examining the relationship between income
and education, r will have the same value regardless if one uses
dollars or yen or marks or pesos.
- For this reason it is called a standardized measure.
- TWO VARIABLE REGRESSION ANALYSIS:
- Correlation is intimately tied to the notion of regression.
- Regression analysis involves two questions:
- Is there a mathematical relationship between X and Y?
- If so, what is this relationship? How can it be described mathematically?
- Some argue that a mathematical relationship expresses a social or political or
economic "law" because it shows how one variable affects another.
- It thus provides an explanation of the variation in a dependent variable.
- A mathematical relationship also leads to prediction: if we know the value of X we
can then predict the value of Y, subject to a certain amount of error if the
relationship is not "perfect."
- The mathematical relationship thus tells us in addition how much error or
indeterminacy exists in the X-Y relationship.
- A relationship of this sort can be expressed in several ways:
- One way is:
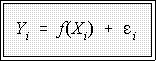
where Yi is a value of Yi,
the dependent variable, f(xi) means "is a function
of X"
and ei
represents a random error.
- Ordinary regression assumes the function
is linear or can be made
linear.
- Example a linear function or relationship:

- Here the function is 2 plus 2 times X. The equation says, in effect,
that scores on Y are produced (are a function of) by X. In
particular, a Y score equals 2 plus 2 times a value of X plus an
error. Thus if we know the value of X we could plug it into the
formula and get a predicted score for Y. The error part is indicates
that the function does not perfectly describe the dependent variable
Y.
- The goal of regression analysis is to estimate the function--to find the equation that
links X to Y. One hopes that the error part will be as small as possible because the
"data" will then nearly equal the "fit." Another way of saying this is that one wants
to reduce the error so that the predicted values of Y will be as close to the
observed values as possible.
- What leads to a "good" fit?
- An appropriate independent variable(s)
- A correctly specified or estimated relationship
- LINEAR MODELS:
- Linear relationships
- A useful mathematical relationship that "fits" a surprisingly large number of
data sets is a linear equation between X and Y. It has the general form:

- Interpretation:
- a is the "intercept": it is the value of Y when X is 0
- b is the "slope": the amount Y changes for a one-unit change in X.
- The graph of the data point that fit a linear relationship is a straight line.
- Geometry of a linear relationship
- Example: consider these observed values for X and Y given the
relationship--Y = a + bX.
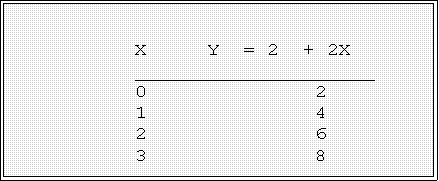
- Here is the graph of these data:. Notice it is a straight line.
- Here a = 2 and b = 0
- As X increases by 1, Y increases by 2. When X = 0, Y = a = 2.
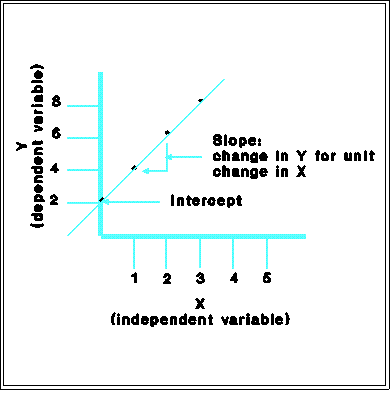
- Interpretation: the graph of a linear relationship or function is a straight line
with "slope" equal to b and "intercept" equal to a. If a set of data seem to
fall on or near a straight line, one can infer that the variables are linearly
related.
- REGRESSION PARAMETERS:
- The constants a and b are called regression coefficients.
- In keeping with our standard notation we'll use Greek letters to denote
population parameters.
- b
(b),
usually considered the more important of the two, is called the regression
coefficient.
- It indicates the amount that Y changes for a unit change in X.
- That is, assuming the linear model holds, if one could some increase X one
unit, the numerical value of b would tell how much Y would change.
- Suppose the regression coefficient equals 10. Then a one unit change in X
"leads" to or is associated with a 10 unit change in Y.
- If b equal -5,
then changing X by one unit would decrease Y by 5 units.
- Important: b or
beta is measured in units of the dependent variable.
- Suppose, for instance, we are regressing income (Y) measured in
dollars on X, years of education.
- If beta equals 4,000, we would conclude that a one year increase in
schooling would produce $4,000 more income.
- Note that we should write b = $4,000 since the unit of Y is
dollars.
- Another example: suppose we are examining the relationship
between the poverty and crime rates. If Y is the number of violent
crimes per 1,000 citizens and X is the poverty rate (percent
individuals living below the poverty level) in counties then a
regression coefficient of 2.7 would indicate that for every one
percent increase in poverty we would expect the crime rate to go
up by 2.7 crimes per 1,000 population.
- Finally, if we were relating X, GNP per capita measured in tens of
thousands of dollars, to illiteracy (measured as percent of the
population that cannot read), a coefficient of -6.2 would mean that
as a nation's GNP increases one unit (or $10,000 in this case)
illiteracy would fall 6.2 percent.
- Since b is measured in units
of the dependent variable it is often
difficult to compare regression coefficients for different variables.
- a (a)
is the regression constant.
It indicates the value of Y when X equals
zero.
- Example: if a equals 100,
then Y equals 100 when X equals zero.
- In many instances the constant is of secondary
importance in an analysis.
- In fact, it sometimes doesn't make theoretical
sense even if a regression
program produces an estimate.
- For example, suppose as above we are relating GNP to illiteracy. If
a turns out to be 88.1, the literal interpretation is that if a country
has no GNP (X = 0), we would expect its illiteracy rate to be 88.1
percent. But in this situation how meaningful is X = 0?
- In the example of illiteracy and GNP the regression equation would be written:

- LINEAR REGRESSION:
- The two constants or parameters combined with the independent and independent
variables and an error term define a linear regression function, which in our new
notation is:
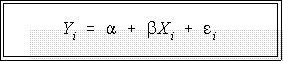
- We'll consider this equation or function
or model in more detail next time.
- For now a another word about the correlation coefficient.
- CORRELATION COEFFICIENT AGAIN:
- The correlation coefficient is often used to evaluate the "fit" of a linear model to an
observed batch of data.
- Recalled that the total variation in Y is called the total sum of squares.
- Recall in addition that this total can be broken into parts:
- "Explained" by the independent variable, X, sum of squares and
- "Unexplained" or error sum of squares.
- Sums of squares are additive

- One of the objectives of regression
analysis is to estimate the explained
sum of squares and what portion of the total it constitutes.
- Another interpretation of r, the correlation coefficient:
- r-squared: r2, the second most
commonly cited statistic, is often interpreted
as the amount of variation in Y "explained" by X. The formula for r2 is,
loosely speaking:

- r2 is normally written with a capital, R2
- r squared gives the portion of the total variation in explained by a
regression model.
- One might be tempted to think that r could be used to measure the
"importance" of a variable in explaining some dependent variable.
- After all, an X variable that has an R2 = 80
suggests that 80 percent
of the total variation in Y is explained or accounted for by X.
- Although widely used for this purpose, it can be a
misleading indicator and (in my
view) should seldom if ever be used to
measure the explanatory importance.
- Example: debates about IQ frequently turn out to be duels between
r's. Some investigators assert that a high value of R2 (say, .45)
between race and IQ shows that "nature" is a more important
explanation of intelligence than "nurture" because the r between,
say socio-economic status and IQ may be smaller (e.g., R2 = .25).
- This line of argumentation is often misleading if not down right
fallacious, but it is very common.
- NEXT TIME:
- Further discussion of regression
- More formal definition of the parameters.
- Calculations
- Numerous examples
- Problems of interpretation
 Go to Statistics main page
Go to Statistics main page
Go
to H. T. Reynolds page.
Copyright © 1997 H. T. Reynolds