The next example is a little more complex than the preceding ones. It is an exploratory analysis of the influence of the proportion female in one's occupation on earnings.
It is intended to illustrate the use of the means procedure to output a data set and the use of a merge statement. Since the variable female is a dummy variable, its mean gives the proportion female. Using the statement: by occ80; in the means procedure instructs it to calculate the proportion female for each occupation (1980 census 3-digit codes).
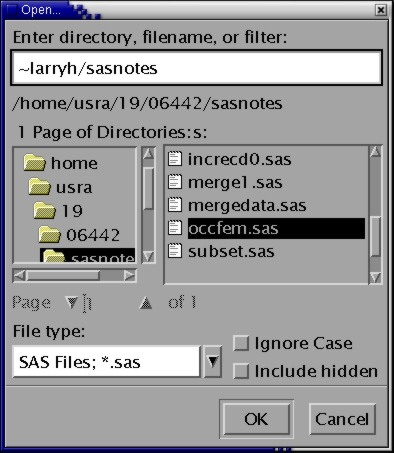
To save time, the command file for this exercise is already written. First, be sure the Program Editor is empty, then open the file --
Before submitting the job, enlarge the Program Editor so you can see all of the program. Then note --
Now run the job and view the output. The results show that the
proportion of workers in an occupation who are female influences
income, irrespective of one's own gender.
Merging is an important concept in SAS. It allows you to combine variables (not cases) from two or more SAS data sets. It is helpful to classify merges into three types --
The one-to-one merge without a by statement requires that the observations for the two (or more) data sets be matched exactly for each case. To avoid mismatches, both data sets must be sorted in the same order, and they must contain exactly the same cases (this implies the same number of cases).
The one-to-one merge with a by requires presorting of all data sets to be merged but does not require that every individual (city, county, state, firm, ... etc.) who appears in any one file also appear in every other file. SAS will not combine cases for which the by variables (e.g., id number, social security number, name) do not have the same values.
The many-to-one merge allows attaching values of an aggregate, such as school, city, state, occupation ... to each individual record, as illustrated in the example with proportion female in an occupation.
As another example, you may wish to attach the proportion of cloudy days in cities to the record of every person who lives in the city. Say you want to study the effect of cloudy days on clinical depression.
The basic structure of a merge with a by statement is --
proc sort data=a;
by id;
run;
proc sort data=b;
by id;
run;
data ab;
merge a b;
by id;
run;
If you leave out the by statement following the merge statement, you have a one-to-one merge without a by. If, say, observations in data set a were for individual students, and the observations in data set b were for schools, then you would be merging school information onto student information and have a many-to-one merge.
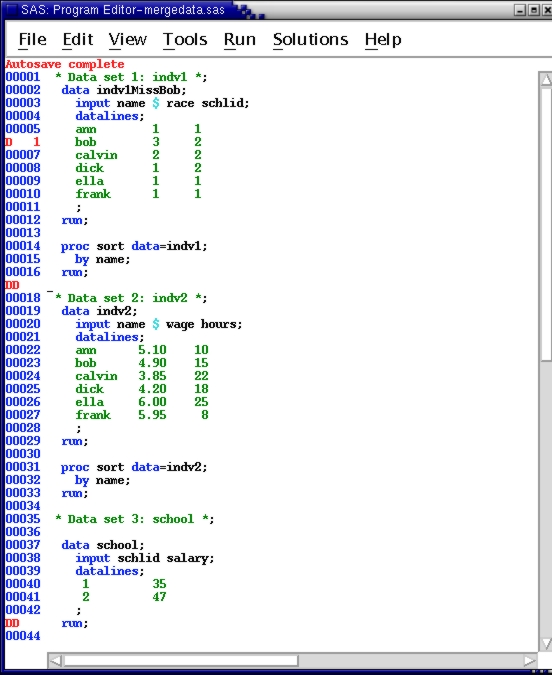
The following examples illustrate several uses of merging. These examples use the following data sets:
Data set 1: indv1
Name race schlid
ann 1 1
bob 3 2
calvin 2 2
dick 1 2
ella 1 1
frank 1 1
Data set 2: indv2
Name wage hours
ann 5.10 10
bob 4.90 15
calvin 3.85 22
dick 4.20 18
ella 6.00 25
frank 5.95 8
Data set 3: school
schlid salary
1 35
2 47
The salary variable is the school-average annual teacher salary in thousands of dollars.
To start the examples, clear the Program Editor and open the file --
This program creates and sorts three small data sets for use in the merge exercises. he data are read from inside the program, using the datalines statement:

Save this program to a file named mergedata.sas. Then submit it to generate the data sets.
After it runs (correctly), go to the Explorer Window and select . (Right click and release on to select.) The two small data sets we just created are listed. Select both of them. They open in spreadsheet-like windows. Make the columns and windows small enough so they interfere as little as possible with other windows on your screen.
Merge 1: One-to-one, no missing cases, WITHOUT a by statement.
Merge 2: One-to-one, no missing cases, WITH a by statement.
Clear the Program Editor Then type the following short program. It contains two data steps. One merges the two small individual-level data sets we just created without a by statement and the other does the same thing with a by statement --
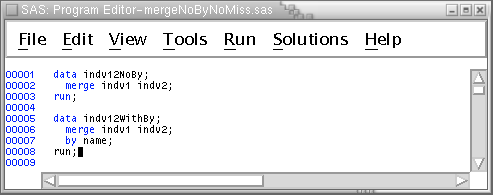
Remember that the input data sets are already sorted by the name variable.
Run the program. The names of the two new files just created should appear in your Explorer Window. Open them and resize them as you just did for the input data sets (indv1, indv2). The output files exactly match each other. This exercise shows that merging without a by statement works providing both (all) files are sorted by the ID variable(s), and there are no missing obversations in either (any) of the files to be merged.
Merge 3: One-to-one, one missing case from indv1, NO by statement;
Now suppose we had no observation for bob in indv1 and merged without a by statement. First, reopen the progam we used to create the (mergedata.sas) data and --
Use the D and DD prefix commands to do the deletions --
Press  to delete the lines, then submit the job. Take a look at the new data set
to confirm it has no observation for bob: Go to the Explorer Window again and select
indv1MissBob..
to delete the lines, then submit the job. Take a look at the new data set
to confirm it has no observation for bob: Go to the Explorer Window again and select
indv1MissBob..
Next, merge this new version of the first individual-level data set, indv1MissBob with the second individual-level data set (indv2) WITHOUT a by statement --
Take a look at this output data set to see what happened. (Go to the Explorer Window and select indv12NoByMissBob. Compare this to the original merge --
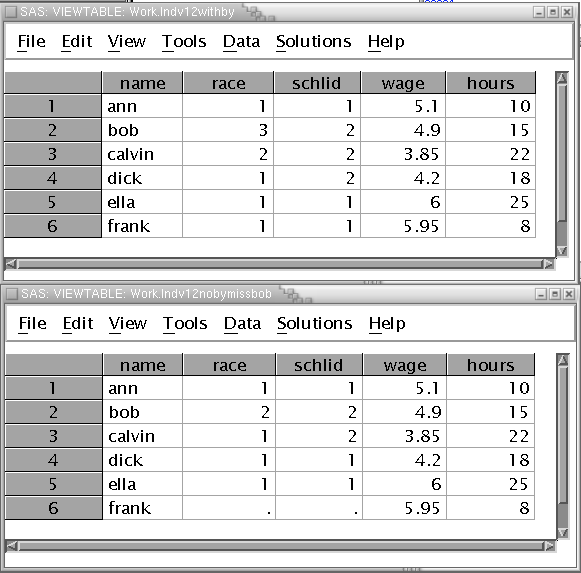
(Top image is correct.) Note that race and schlid moved up a case for observations from bob on, and race and schlid are missing for Frank. Wage and hours, on the other hand are correct for all cases. This has the potential for a disaster!. Any procedure that analyzes simultaneously some variables from indv1 and and some from indv2 will report nonsense. For example, the correlation between wage and race mostly correlates race of one person withwage of different person!
But if you merge with a by statement, this does not happen. Recall the program and insert the by statement --
Merge 4: One-to-one, one missing case from indv1, WITH a by statement
Type the following short program into the Program Window:
Submit the program then go to the Explorer Window and open the new data set (indv12WithByMissBob). Resize it and place it under the previous data set (indv12NoByMissBob), merged without a by statement.
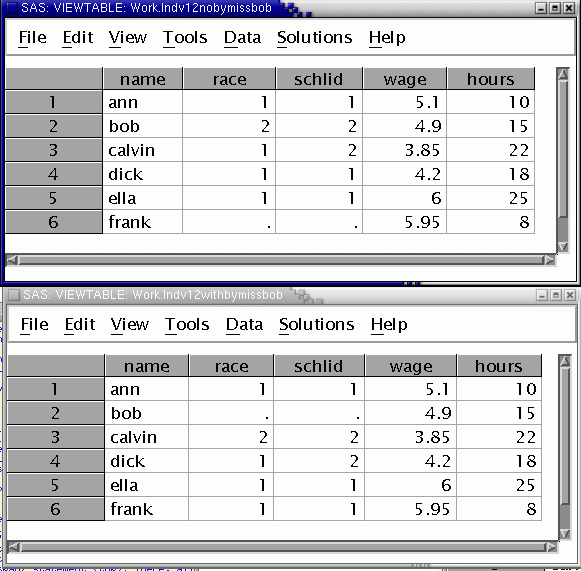
Notice the differences: In the new data set (bottom), the two variables merged from the first data set, race and schlid are missing for bob. This is correct. Bob is the one without data in the first input data set. All the other values are correct. Contrast this to the merge run without the by statement (top). As we just saw, there, all the values for the two variables merged from the first input data set are wrong, starting with bob and continuing to the end.
Merge 5: One-to-many merge, WITH a by statement
The next examples merge school data onto each student's record (the merged individual file, indv12WithBy). In the first example, there is no by statement after the merge, and the match is not correct. The second example uses a by statement after the merge. The school data on teacher's salaries match to the correct students.
Look at all three data sets: indv1, indv2, andschool. Notice that the school data set is sorted by school ID but the student data sets are not. All data sets to be merged must now be sorted by the schlid variable. Before sorting indv12withby, be sure the viewtable displaying it is closed. Otherwise, it won't sort, because it is locked.Sort the indv12withby data set. Then execute the two merges, one without and one with a by statement --
Again, the merge done without a by statement produces demonic results --
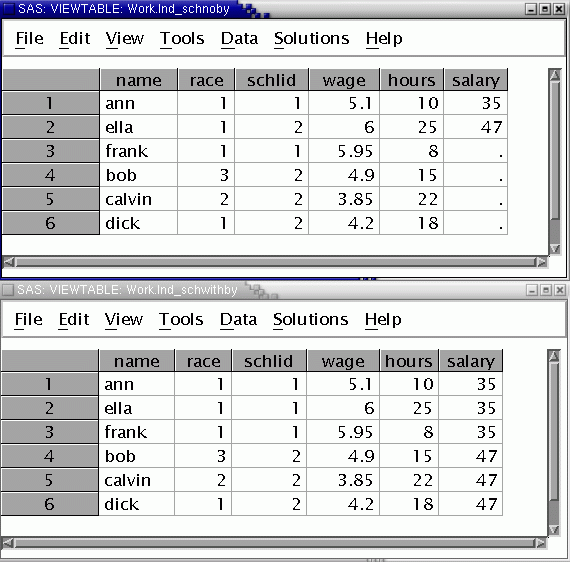
In the first data set, merged without the by statement, only Ann has the correct teacher salary assigned to her. Ella has the wrong teacher salary, and the rest of the teacher salaries are missing. In contrast, all the assignments are correct in the second data set, merged with a by statement.
A userul diagnostic that this has happened is excessive number of missing values for all variables taken from the school file.
The SQL procedure can be used for many purposes. It is a more flexible way to produce reports than proc print, for example. It also can be used to merge data sets. Often it does the merges more quickly than a data-step merge, does not need data to be sorted before the merge operation, can sort the output data set and does not require the match variables to have the same name in all the datasets to be combined. The merges we just performed, for example, can be done with proc sql.