Common errors in SAS jobs include --
The saslog contains diagnostic messages to help you identify errors. These appear in the Log Window as --
ERROR: NOTE: WARNING:
But these messages seldom are as clear as "you left out the semicolon on line 3" or "you misspelled the variable gender." Hence, debugging is something of an art, and it can be very frustrating. We will illustrate each of these mistakes in the next exercises.
Understanding the proper order of SAS statements is a big help in getting your jobs to run correctly. In many cases, the order of two statements may be reversed without affecting the results, for example --
proc means; proc means;
var x y z; OR class abc;
class abc; var x y z;
run; run;
will yield the same results.
But, statements that belong in a data step usually are not permitted in a proc step. And statements that belong with a specific procedure often are not permitted anywhere else. However, many statements are used in several procedures. For example, a var statement is not permitted in a data step, but it is permitted in many procedures -- but not in all of them. Also, some procedures permit data-step programming statements (e.g., proc nlin -- nonlinear least squares, proc nlp -- nonlinear programming, programming statements. -- nonlinear least squares, proc model -- nonlinear systems of equations in the ETS package), but most procedures do not permit programming statements.
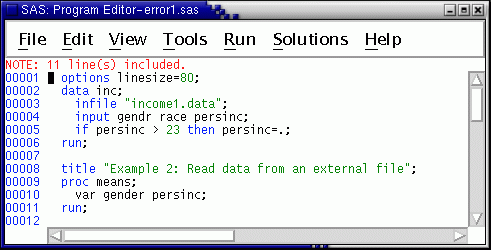
First be sure the Program Editor is empty, then copy income2.sas into the it. Select from the menus in the Program Editor. Change 'gender' to 'gendr' on the input statement, put the second run statement on a new line, then insert a var statement between the proc means statement and the run statement. Indent this line two spaces to show it is part of the proc step. Note the intentional misspelling of gender. The result should look like --
The var statement in proc means identifies the variables to use in the calculations. In files with many variables, you often may want results for only a few.
Run the program and view the results. (Press the F3 key or select from the menus.) Since the job contains errors that prevent the means procedure from executing, nothing is written to the Output Window.
Note the error in the saslog --

ERROR: Variable GENDER not found. This error might be a bit perplexing if you had not just purposively misspelled gender on the input statement. The reason for this error is that the SAS data set does not, in fact, contain a variable called gender. Rather, it contains one called gendr.
Next, recall (if necessary) the program we just ran by pressing the F4 key. Fix the misspelling of gender on the input statement and move the var statement to the data step --
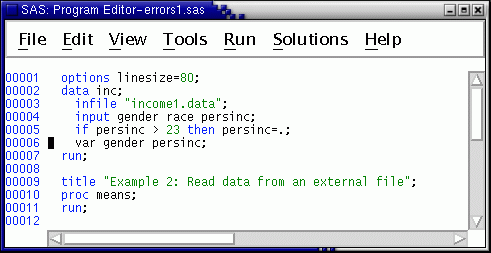
Before running this job, (if necessary) go to the Log Window and clear it out by selecting . Clearing the log between runs often is useful, because it avoids confusion about which lines in the log refer to the current submission. This is particularly useful if you are debugging a program or doing test runs to find out exactly what analysis you want to do.
Now, run the job (Press the F3 key or select from the menus.) Note the error diagnostic messages in the Log Window --
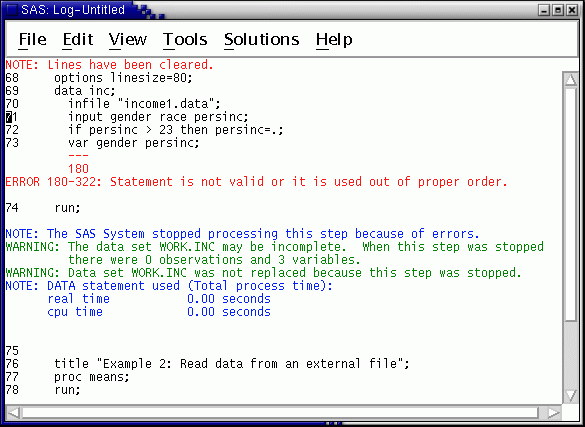
This log contains both an ERROR and two WARNING messages. The var statement is not recognized because it is not allowed in a data step.
The next exercise shows one thing that can happen when you omit a semicolon (;). Remember that all SAS statements must end with a semicolon! Recall (if necessary) the program (F4 key). Move the var statement back where it belongs, after the proc means statement. Then remove the semicolon from the data statement, like this --
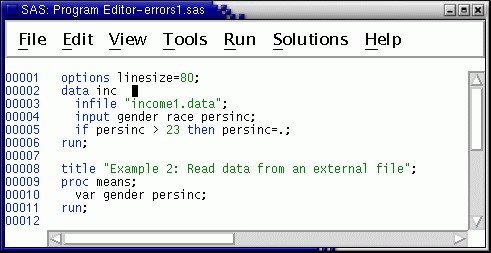
Again, (if necessary) clear the log, then run this program. The log contains several diagnostics --

The reason for these diagnostics is that, due to the missing semicolon at the end of the data statement, the infile statement now is considered to be part of the data statement. The infile keyword is not recognized because it is not the first word after a semicolon and therefore isn't the first word in a SAS statement.
This exercise shows what can happen when you forget to close a quotation mark. Recall (if necessary) the program to the Program Editor (F4 key) again. Put the semicolon back where it belongs at the end of the data statement and remove the trailing quote from the file name, like this --
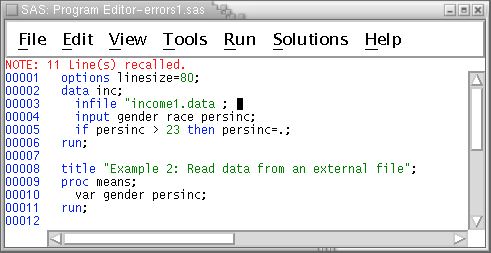
Clear (if necessary) the log again, then run this program. The log contains several diagnostics --
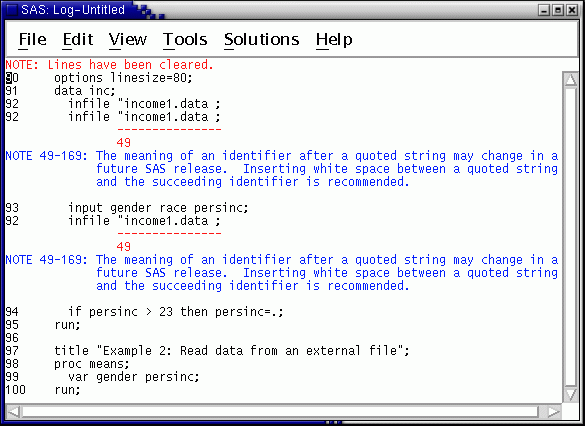
The diagnostics could be confusing. The first diagnostic is a NOTE. It mentions a quoted string but does not say it is unbalanced. In fact, SAS considers the string to continue until the next quotation mark, in the title statement. There is no mention of an unbalanced quote.
Recall (if necessary) the program, fix the error and rerun the job.
Notice how the color codes change after you insert the missing quote
mark and press the  key.
key.
But we are not out of the woods yet. Submit the program and look at the saslog again. It still reports errors. That's because the SAS session continues and still encounters an odd number of quotation marks. Try submitting one line containing a quote mark and a semicolon. Then recall (if necessary) the program twice. The first recall retrieves the line with the quote and semicolon. Delete this line. Then recall the program again and rerun it. More errors are reported, but it finally runs correctly. Sometimes, it's simpler to exit SAS and start over.
Note: You don't encounter this type of compounding of problems if you run SAS batch, because each submission starts a new SAS session. So leftover quotes are not remembered.
The next exercises show how SAS responds to errors in the data file. First, copy the data file income1.data to a new file, income2.data so we have a master copy of the data that is not corrupted. Then use the pico editor to change all the 99s in the income columns to the letter ' M' with a leading space in place of the first 9.
cp income1.data income2.data
pico income2.data
The result should look like --

Be sure the Ms are located in column 8 (under the one's digit in the income field).
Next --
The program should look like this --
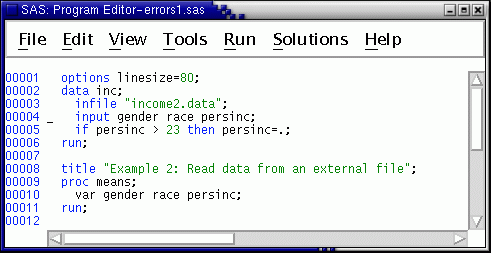
The output is still correct, but the log contains notes about invalid data.
Edit income2.data using pico. Change the 'M's to blanks. Be sure you have blank spaces to replace the Ms, at least out to column 8, like this --

Also, add a proc print statement to the program --
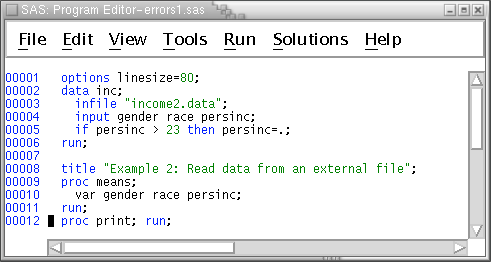
Clear (if necessary) the Log Window and the Output Window. Then run the job (Press the F3 key or select from the menus.) and view the results. Check the saslog first. Note particularly the NOTE in the sas log --
NOTE: SAS went to a new line when INPUT statement reached past the
end of a line. Any time you see this note, it's likely to be a
problem. Two other SAS NOTES also raise the caution flag --
NOTE: 10 records were read from the infile "income2.data".
NOTE: The data set WORK.INC has 8 observations and 3 variables.
The number of lines read from the data does not match the number of
observations written to the SAS data set. To see what happened,
look at the
output.
Note that the number of cases and descriptive statistics are different
than they were in the previous runs. This is because SAS went to a new
line in both lines where we deleted the M.
To understand what happened, compare a listing of the complete data set as SAS interpreted it to a previous printing when there were no errors in the data --

As indicated by the hand-drawn circles and lines, when SAS went to a new line, it picked up the value of gender for person 3 and put it into persinc for person 2. The rest of line three is ignored; SAS starts a new case at line 4 which becomes the third observation in the SAS data set. The same thing happens again when the second blank is encountered for persinc. The value of gender for person 10 is assigned to persinc for person 9 which becomes the eighth observation in the data set.
This could be pretty nasty if not detected before "going to press," particularly if the data contain many blanks. If there are only a few blanks in the data, this error might go undetected, but the more blanks, the more likely it is to be detected.
The errors generated from using blanks for missing values, as just illustrated, are particularly troublesome. A safer way to read data, especially from a large input file, is with column indicators for each variable, as in Exercise. The SAS program for this exercise was saved in the file income3.sas.
Retreive that file now into the Program Editor. Change the name of the input data file from income1.data to income2.data. Clear the Log Window and the Output Window, and run this program. Then view the results. Notice that the saslog now contains no NOTEs about SAS going to a new line, and the number of lines read from the file now matches the number of observations written to the SAS data set (10).
Next, get the file we used to read the GSS data. Go to the Program Editor, clear it and select . Pick the file named gssread.sas. Rerun this program.
Recall this program. To emphasize the importance of setting missing values, make the line which sets the missing value for rincome98 a comment, like this --

Compare the output from the two runs of the means procedure.

Note how statistics for rincom98 are distorted (correct mean and standard deviation: 14.412, 5.687; incorrect mean and standard deviation: 18.900, 18.533). Also note that the maximum value of rincome98 jumped from 23 to 99. Again, check the codebook:
But remember that treating any missing value as if it were a correct number degrades your analysis. For instance, if you code a dummy variable like this --
if marStatus=1 then married=1; else married=0;
then any missing values on marStatus are coded as not married (married = 0). Unless you know the "parent" variable has no missing values, it's better to code --
if marStatus ^= . then do;
if marStatus=1 then married=1; else married=0;
end;
If you forget to set missing values, similarly miserable results will occur for other statistics like correlations and regression coefficients. You could easily end up inventing a theoretical explanation for a regression finding based largely on missing values!