AGGREGATE FUNCTIONS
Aggregate functions are
math or statistical functions that apply to
sets or subsets of data rather than to individual instances (rows).
Examples
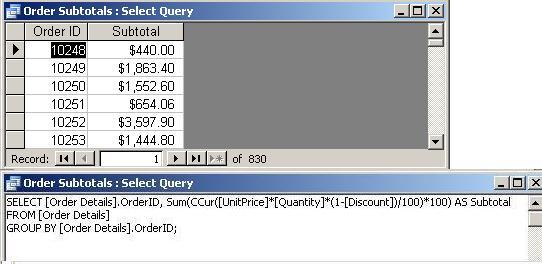
- Order
Subtotals: The (discounted) total $
amount for all items in each order
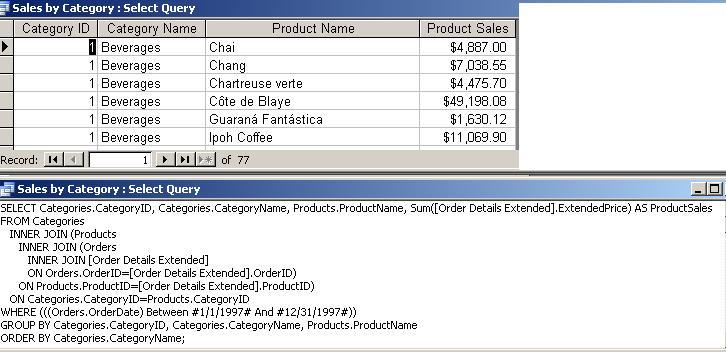
- Sales By
Category: The (discounted) total $
amount for each product, by category, for 1997
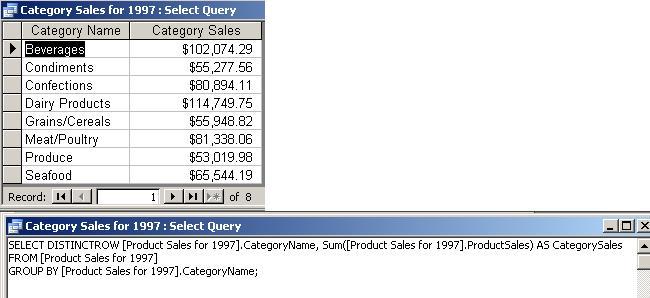
- Category
Sales for 1997 (based
on next query): Total sales, by
category, for 1997
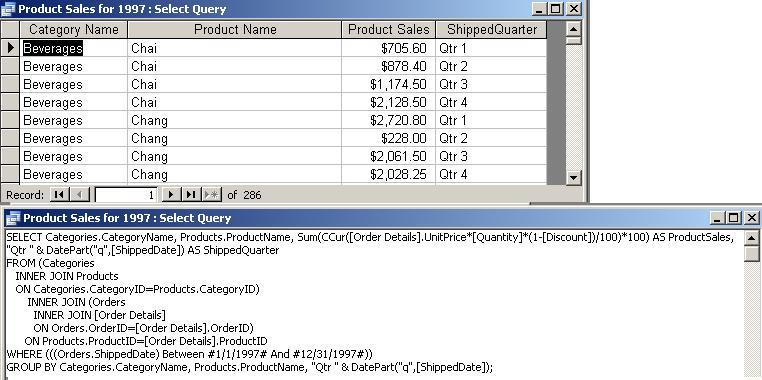
- Product
Sales for 1997: Total product sales, by
quarter, for 1997
The
standard
aggregate functions are MIN, MAX, AVG, SUM,
and COUNT.
They
are almost always used with
GROUP BY to create the subsets
with WHERE
before GROUP BY to set criteria before
calculating
and
HAVING after
GROUP BY to set criteria
for the calculated results
The GROUP BY clause must include all columns in the SELECT clause
except the calculated aggregate columns. Grouping occurs from
left to right, as written in the GROUP BY clause, and groups "break"
(to a new group) as soon as a different column value appears in the
left-to-right order. For example, in the last query
above, note the break between Chai and Chang, and the individual breaks
for each quarter. Scrolling down in the query, there is a break
(a new group or subset) for each product category.
- What
would you expect to see if you used an aggregate function in a query
but did not include a GROUP BY clause?
Note on
aggregate functions and nulls: The
aggregate functions do not include rows that have null values in the
columns involved in the calculations; that is, nulls
are not handled as if they were zero.
The only function that can return
a value for all rows, regardless of the presence of nulls is the COUNT
function:
E.g. COUNT(column_name)
returns a count of all rows where the value of column_name is not null,
but
COUNT(*) returns the count of all
rows, even those with
nulls in column_name
AGGREGATE FUNCTIONS
Exercise - modify an existing
query
- Run the
Category Sales for 1997 query, change to SQL view, and save as Sales
Over 100K
To see only
sales totals greater than $100000, add the following criteria after the GROUP BY clause:
HAVING Sum(ProductSales) >
100000
Run the query
and compare the results with the original query - totals should be the
same but there should be only two rows.
- Save the
original query again as Product Sales First Quarter. To see only
totals for the first quarter, add
the following criteria before
the GROUP BY clause (ShippedQuarter is a
column
in the Product Sales for 1997 query):
WHERE ShippedQuarter like
"*1"
Run the query and compare the results with the original Category Sales
for 1997 - all totals should be substantially lower.
- Change to SQL
view and save as First Quarter Sales Over 20K. To see only totals
greater than $20000, add the following
criteria after the GROUP BY
clause:
HAVING Sum(ProductSales)
> 20000
Note:
No need to include the table or query name \226
the ProductSales column only appears in one of the tables or queries.
Run the query
and compare the results with the previous query - only 4 values are
selected.
Exercises using other aggregate functions
(Note: None of these exercises require more than one
table.)
- How many
different products are represented in the database?
- How many
products are there in each category?
- Find the
average freight charged by each shipper.
Modify the original freight query:
Average
freight by shipper for freight above
$75
Modify the original freight query:
Average
freight by shipper showing only
averages above $75
- Find the
most popular product (as measured by how many ordered).
- Find the
most expensive product.
-
Practical
example (contrived in this database):
Find duplicate (or
more) product listings in Order Details.
Find duplicate (or more)
product-price pairings (same product and price) in Order
Details
(Compare with Find Duplicates wizard
in each case)
COMPLETE SYNTAX FOR
SELECT STATEMENT
SELECT
column list, function(), function(),
...
FROM
table1
INNER JOIN
table2
...
ON table1.col1 =
table2.col2
...
WHERE criteria
for row selection
[AND
criteria for row
selection]
[OR criteria
for row selection]
GROUP
BY
column
list
HAVING criteria
for function results
ORDER BY
column
list
SUBQUERIES
Subqueries
are used to
structure queries. In many cases, a subquery can be used
instead of a JOIN (and vice versa).
For
database systems fully compliant with the SQL 92
standard, a subquery can also be used to provide one or more values in
the SELECT clause.
In
most database systems, subqueries are typically
part of the WHERE clause, as follows:
- WHERE
column IN
(subquery
- WHERE
column <comparison>
(subquery)
The
subqueries
themselves are complete SELECT
statements, enclosed in parentheses.
Examples
&nb
sp;
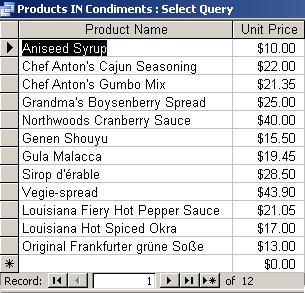
Find
the
price of all products in a particular category, for example
condiments.
Type
this query in the SQL window and check against the result shown
below:
SELECT ProductName, UnitPrice
FROM Products
WHERE CategoryID In
(SELECT CategoryID
FROM
Categories
WHERE
CategoryName = "Condiments");
This JOIN should give the
same result:
SELECT ProductName, UnitPrice
FROM Products
INNER JOIN Categories
ON Products.CategoryID =
Categories.CategoryID
WHERE CategoryName =
"Condiments";
Run
the query
Products Above Average Price; check in SQL
view (shown here):
SELECT
Products.ProductName, Products.UnitPrice
FROM
Products
WHERE
(((Products.UnitPrice) >
(SELECT AVG([UnitPrice]) From Products)))
ORDER
BY
Products.UnitPrice DESC;
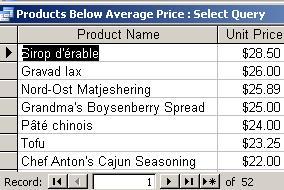
Modify
the query to
show products below average price. Results (formatting
removed):
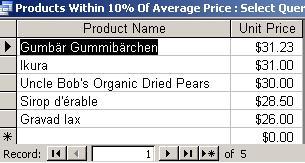
Modify
again to show products within plus or minus 10% of average price
(requires some calculations)
&nb
sp;
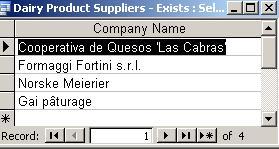
Create
a
list of suppliers from whom we buy dairy products. Type the
following query in the SQL window - use the INNER JOIN ... ON
syntax in the subquery, if you prefer.
SELECT CompanyName
FROM Suppliers AS s
WHERE EXISTS
(SELECT
*
FROM Products p, Categories
c
WHERE
p.SupplierID = s.SupplierID
AND
p.CategoryID = c.CategoryID
AND
CategoryName LIKE "*Dairy*");
Result:
SUBQUERIES
Exercises
Create
a
list of customers located in the same city as a supplier, showing
company name,
city, and country (try with a subquery and check with a
join). (14 rows)
Find
all
freight charges that are greater than average and list along with the
shipper's
name (find the average first, as a check). (242
rows)
How
many
shipments has each shipper made at charges greater than average?
(3 rows, 2 or 3 columns)
Which suppliers do not
sell dairy products? (25 rows)
SUBQUERIES:
SYNTAX
SELECT column
list
FROM
table(s)
WHERE
<column_name>
[
IN
|
<comparison>
|
EXISTS]
(SELECT column
list
FROM table(s)
...
)
[AND | OR additional criteria]
GROUP BY
...
HAVING
...
ORDER
BY column list
SELF-JOIN
A
self-join
is a query in which a table is joined (compared) to itself. Self-joins are used to compare values in a
column with other values in the same
column in the same table. One practical use for
self-joins: obtaining running counts and running totals in an SQL
query.
To
write
the query, select from the same table listed twice with different
aliases, set
up the comparison, and eliminate cases where a particular value would
be equal to
itself.
Example
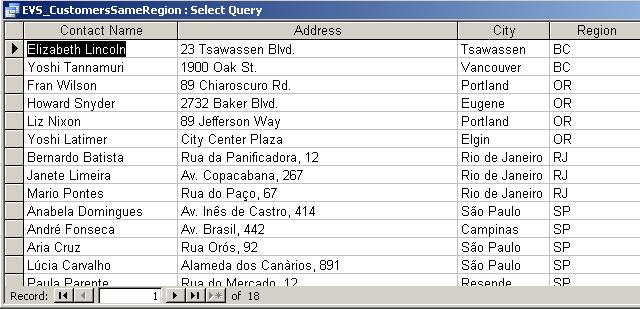
Which
customers are located in the same state (column name is Region)?
Type this statement in the SQL window:
SELECT DISTINCT c1.ContactName,
c1.Address, c1.City, c1.Region
FROM Customers AS c1, Customers AS
c2
WHERE c1.Region = c2.Region
AND c1.ContactName <>
c2.ContactName
ORDER BY c1.Region, c1.ContactName;
The result
should look like this:
Exercise
Which
customers are located in the same city? (32
rows)
STATISTICS
IN SQL
Note: Can be done in the
database, but
best done in a spreadsheet or using statistics software!
EXAMPLES
- Mean: AVG (aggregate function)
- Mode: Count of most frequently
occurring value (combination of aggregate functions and
subquery)
E.g.: Price frequency
(upper result) and mode (lower result)
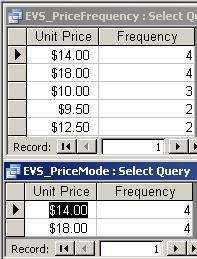
SQL for the two queries:
SELECT Products.UnitPrice, Count(*)
AS Frequency
FROM Products
GROUP BY Products.UnitPrice
ORDER BY Count(*) DESC ,
UnitPrice;
SELECT UnitPrice, Count(*) AS
Frequency
FROM Products
GROUP BY UnitPrice
HAVING Count(*) >= ALL
(SELECT Count(*)
FROM Products
GROUP BY
UnitPrice);
Note: We need the subquery because aggregate functions cannot be
nested.
- Median: Value such that
the number of values above and below it is the same ("middle" value,
not necessarily same as average or mean). (Moved after running
count and running sums because it requires a running count and is more
complex than either.)
- Ranking; running count:
Compare table to itself (self-join) and generate count based on the
comparison.
E.g.: Assign sequential numbers to customers based on
their customer ID.
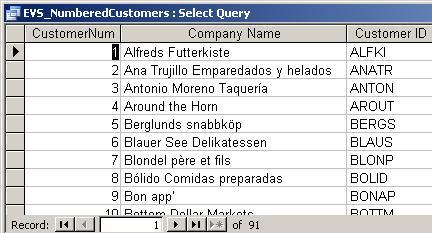 Note:
CustomerNum is not stored in the database - it is generated whenever
needed by running the query.
SQL for the
query:
SELECT
count(p1.CustomerID) AS CustomerNum, p1.CompanyName,
p1.CustomerID
FROM
Customers p1
INNER JOIN Customers p2
ON p1.CustomerID >= p2.CustomerID
GROUP
BY p1.CompanyName, p1.CustomerID
ORDER
BY 1;
Note:
CustomerNum is not stored in the database - it is generated whenever
needed by running the query.
SQL for the
query:
SELECT
count(p1.CustomerID) AS CustomerNum, p1.CompanyName,
p1.CustomerID
FROM
Customers p1
INNER JOIN Customers p2
ON p1.CustomerID >= p2.CustomerID
GROUP
BY p1.CompanyName, p1.CustomerID
ORDER
BY 1;
- Running sum: Compare table to
itself (self-join) and generate totals based on the comparison.
E.g.: Calculate the
running total $ amount by date for orders placed by a particular
customer (ID RATTC). To simplify the SQL, first calculate total for
this customer without generating a running total and then the running
total based on the first query (results below, on the left):
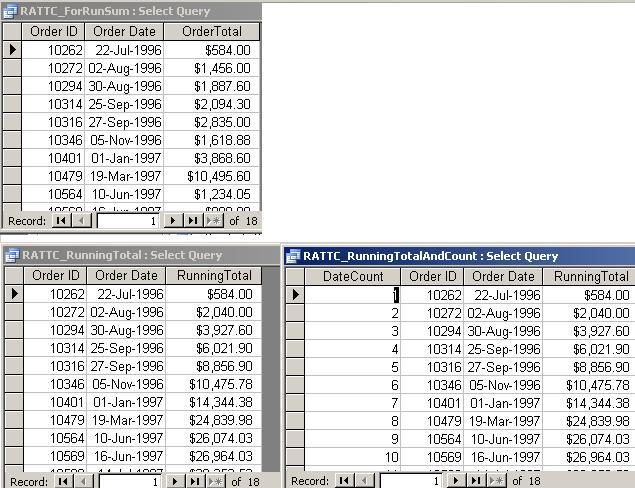
The result on the right includes a running count based on date as well
as the running total.
SQL for the three queries:
Query at top left (RATTC_ForRunSum)
SELECT a.OrderID, a.OrderDate,
Ssum(a.ExtendedPrice) AS OrderTotal
FROM Invoices AS a
WHERE a.CustomerID = "RATTC"
GROUP BY a.OrderID,
a.OrderDate;
Query at lower left with running total only (RATTC_RunningTotal):
SELECT a.OrderID, a.OrderDate,
Sum(b.OrderTotal) AS RunningTotal
FROM RATTC_ForRunSum AS a,
RATTC_ForRunSum AS b
WHERE b.OrderDate <=
a.OrderDate
GROUP BY a.OrderID,
a.OrderDate;
Query at lower right with running total and count
(RATTC_RunningTotalAndCount):
SELECT Count(b.OrderDate) AS
DateCount, a.OrderID, a.OrderDate, Sum(b.OrderTotal) AS
RunningTotal
FROM RATTC_ForRunSum AS a,
RATTC_ForRunSum AS b
WHERE b.OrderDate <=
a.OrderDate
GROUP BY a.OrderID,
a.OrderDate;
- Median:
Value such that the number of values above and below it is the same
("middle" value, not necessarily same as average or mean). The
solution offered here is an approximation - may not work in all
cases.
Also, other database systems have better functions for finding the
"middle" of a sorted list.
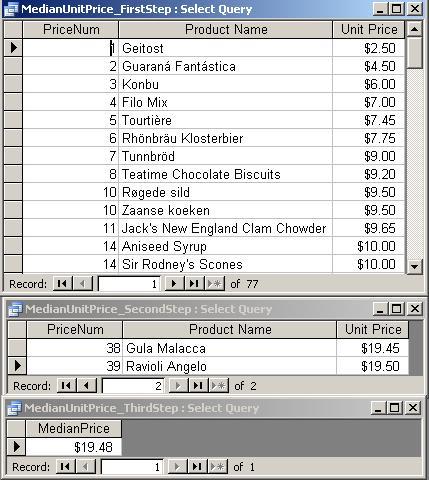
E.g.: Find the
median unit price for all products. Build the query in three
steps (results below the third SQL statement):
- Number
the product list based on UnitPrice:
SELECT
Count(a.ProductID) AS PriceNum, a.ProductName,
a.UnitPrice
FROM
Products AS a
INNER JOIN Products AS b
ON a.UnitPrice>=b.UnitPrice
GROUP
BY a.ProductID, a.ProductName, a.UnitPrice
ORDER
BY a.UnitPrice;
- Find
the middle one or two numbers (added clauses
highlighted):
SELECT
Count(a.ProductID) AS PriceNum, a.ProductName, a.UnitPrice
FROM Products AS a
INNER JOIN Products AS b
ON a.UnitPrice >= b.UnitPrice
GROUP BY a.ProductID, a.ProductName, a.UnitPrice
HAVING
Count(a.ProductID)
Between (SELECT
(Count(ProductID)/2)-0.5
&nbs
p;
FROM Products)
And (SELECT
(Count(a.ProductID)/2)+0.5
&nbs
p;
FROM Products)
ORDER BY a.UnitPrice;
- Average
the results (added clauses highlighted):
SELECT
Avg(UnitPrice) AS MedianPrice
FROM
(SELECT
Count(a.ProductID) AS PriceNum, a.ProductName,
a.UnitPrice
FROM Products AS a
INNER JOIN Products AS b
ON a.UnitPrice>=b.UnitPrice
GROUP BY a.ProductID, a.ProductName, a.UnitPrice
HAVING
Count(a.ProductID)
Between
(SELECT
(Count(ProductID)/2)-0.5
FROM Products)
And
(SELECT
(Count(a.ProductID)/2)+0.5
FROM Products));