This project reviews the following concepts from CISC181:
In addition, this project introduces some (possibly) new concepts:
You will start by implementing a class that represents one line from one file from the Lahman Baseball Database. This file (proj2a.html) covers only this initial step.
A local copy of this database is available in the following places:
/www/htdocs/CIS/restricted/data/baseball/lahman53 In the directory proj2/step01, I've provided some sample code for a class that represents one line from the file Master.csv.
If you look at the first few lines of this file, they look like this:
lahmanID,playerID,managerID,hofID,birthYear,birthMonth,birthDay,birthCountry,birthState,birthCity,deathYear,deathMonth,deathDay,deathCountry,deathState,deathCity,nameFirst,nameLast,nameNote,nameGiven,nameNick,weight,height,bats,throws,debut,finalGame,college,lahman40ID,lahman45ID,retroID,holtzID,bbrefID 1,aaronha01,,aaronha01h,1934,2,5,USA,AL,Mobile,,,,,,,Hank,Aaron,,Henry Louis,"Hammer,Hammerin' Hank,Bad Henry",180,72,R,R,4/13/1954,10/3/1976,,aaronha01,aaronha01,aaroh101,aaronha01,aaronha01 2,aaronto01,,,1939,8,5,USA,AL,Mobile,1984,8,16,USA,GA,Atlanta,Tommie,Aaron,,Tommie Lee,,200,73,R,R,4/10/1962,9/24/1971,,aaronto01,aaronto01,aarot101,aaronto01,aaronto01 3,aasedo01,,,1954,9,8,USA,CA,Orange,,,,,,,Don,Aase,,Donald William,,210,75,R,R,7/26/1977,10/3/1990,Cal St. Fullerton,aasedo01,aasedo01,aased001,aasedo01,aasedo01 ...
The first line contains a comma separated list of all the fields in the file. For the most part, you should choose these field names as the private data members of your class. (We'll note some exceptions below.)
You should also look at the file readme53.txt (via proxy). Note that it contains descriptions of each field in the file Master.csv (see Section 2.1).
Now look at the file baseballMasterTest.cc. Note that this file uses test-driven development (including the class RunTests_C illustrated in lecture on 06/19 and 06/20) to test out a class that corresponds to one line from this file.
Your job in this step is to understand how this program works, including examining the following source code files:
Because of the use of "composition" (explained in the next section), you'll also need to look at the files:
Note that the BaseballMaster_C class (specified in the file baseballMaster.h) uses composition, which in Object-Oriented Design corresponds to the so-called "has-a" relationship between two objects. Note that rather than having six data members to represent various aspects of a players birth, namely:
birthYear,birthMonth,birthDay,birthCountry,birthState,birthCity
we instead store only one data member, birth, that is of type Event_C *. The data member birth is a pointer to an Event_C object. The Event_C object, in turn, includes a Date_C object with month/day/year, and then pointers to fields for the country, city, and state of that birth.
Structuring things in this way saves us a lot of time, because we can reuse this structure for the fields relating to a players death. Instead of
deathYear,deathMonth,deathDay,deathCountry,deathState,deathCity
we just have the data member death.
This technique is called "composition", and it allows us to have just two "get" functions, i.e. getBirth() and getDeath(), instead of having to write twelve get functions, i.e. getBirthYear(), getBirthMonth(), etc.
In the language of object oriented programming, composition is called a "has-a" relationship. That is, we say that
Once you have understood the code from step 1, now you are ready to get started on your own code. You need first to choose a topic. Look at the file readme53.txt (via proxy) again, and look at the list of data files other than the master file (sections 2.2 through 2.21).
Your job in this step is to choose one of these as the topic of your project 2. Try to make sure you understand the data in the file you choose before you select it. Look at the actual data for that file also by consulting the data directory (via proxy)
If you are not very familiar with baseball, you may need to do a bit of background research to understand the table you select. I'll set up a wiki page so that you can ask for help from those in the class that are more familiar with baseball statistics.
Once you have chosen one of these files, record your selection on the Wiki, on the page:
http://jaguar.cis.udel.edu:8051/220wiki/Wiki.jsp?page=06J.Proj2
Note the additional rules on that page also.
My suggestion is that you proceed like this:
Now repeat those steps until you have code for every field in your file.
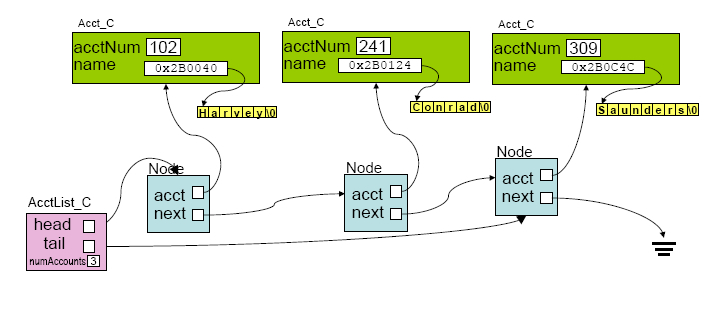
Look at the following diagram. It corresponds to a data structure for a class Acct_C, and a class AcctList_C. The Acct_C class has only two private data members: an account number (stored as an int), and a name (stored as a C-string, allocated separately on the heap.) The AcctList_C class has only two private data members: a head and a tail pointer that point to the head and tail of a linked lists of "Node" structs. Each struct has only two members: a pointer to an Acct_C object (on the heap), and a pointer to the next node.
Your job is to write code for classes that will build a corresponding structure for a list of the baseball data in the file you selected to work with in Step 2. We'll talk more about this in lecture on Wednesday and Thursday.
Note: you can find versions of the diagram below in PowerPoint, PDF, png and jpg format in the directory proj2/step04
In the file acctList.h, you'll find a file that provides an idea about how to proceed with writing the linkedList class. We will also cover this in lecture on 06.21, so consult the lecture notes on the Wiki for that day, and the lecture code directory.
What we want to write is a main program that takes the filename on the command line, and then presents the user with four menu options:
f: find record l: list records s: summarize list q: quit
The program will start by reading all the records from that file into a linked list. Since the files are already sorted, we won't worry about creating a sorted list—we'll maintain the order from the file.
Note that when reading the files, you'll want to skip over the first line in the file (since it contains field descriptions rather than actual data.)
Then allow to search for records by the primary key, list the records, summarize the list (with a count of the records), and quit.
For your list option, don't try to print all the fields---just print a sample of the fields---as many as will fit comfortably in 80 characters wide. Be sure, though, to include the primary key.
If you aren't sure what the primary key is, ask!
To finish up, you need all of the following: