Transcribed by Ed Cox, Edited by P. Conrad
// CISC181-010 notes from 21Apr06
input file on the disk containing 5 numbers
9 |
could be 5, 500, or 5 million numbers
We don't know how many lines are in the file.
9 |
The "dot dot dot" shows that we don't really know how many lines are in the file.
We need to make our array as big as the file could EVER get.
This means we will waste a lot of space, most of the time, i.e. when the file is smaller than the max.
const int MAX_SIZE = 5000000;
int main(void)
{
int nums[MAX_SIZE];
(1) Array size chosen at compile time
advantage: simplicity
disadvantage: wasted space
(2) Array size chosen at run time
e.g. specify on command line
advantage: can be whatever size we need, and can be used like a regular array
disadvantage: must know FROM THE START how large the array must be.
(Or, if the array needs to be bigger, we have to allocate a new array, and copy everything from the old smaller array, which takes up time.)
(3) linked lists
They can grow or shrink to whatever size we need them to be.
disadvantage: more detailed programming than arrays, overhead of pointers
advantage: no wasted space, no arbitrary limits on how large they can grow.
// example program for dynamic arrays
#include <iostream>
#include <fstream>
using namespace std;
#include <stblib> // for exit() asqueir 3pts
int main(int argc, char *argv[])
{
if(argc>MAX_SIZE)
{
cerr << "usage:" << argv[0] << "numOfElements filename" << endl;
exit (1); // aleake 2pts
}
int numElems = atoi(argv[1]); // bflad 2pts ifstream infile( argv[2] , ios::in); // bwadswor 1pts if( !infile) // cyacco 3pts
{ cerr << "error: could not open" << argv[2] << endl; exit(2); // mguerrer 3pts }
// everything above this line stays the same for link lists
// allocate the array. allocate with new. return it with delete
int *nums = new int[numElems];
int x; // number from file
int count = 0;
infile >> x; // try to read
while(!infile.eof() ) // while not eof
{
// process the data
nums[count] = x;
i++;
if(i>=numsElems)
{
break;
}
// try to read again
infile >> x; // pdongmo 3pts
}
infile.close(); //close is a member function
// now use the array
...
return 0;
}
We run the program by saying
./ a.out 500 nums.dat
or
./myprog 5000000 lotsanums.dat
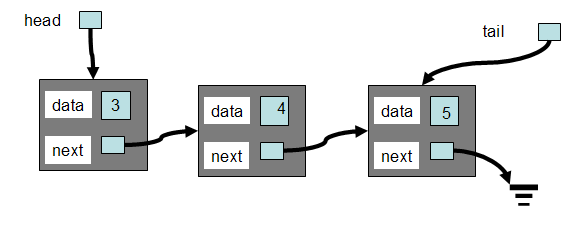
In practice drills for teaching linked lists, we will often construct lists using a Node_S structure, to build lists like these:
The following is a "generic" node in a linked list that we often use in examples. It just stores a linked list of integers.
struct Node_S
{
int data;
Node_S *next;
};
Sometimes students think that there is something "special" about the word "Node" or "Node_S". There isn't. That's just a name we use for a "generic" item in a linked list.
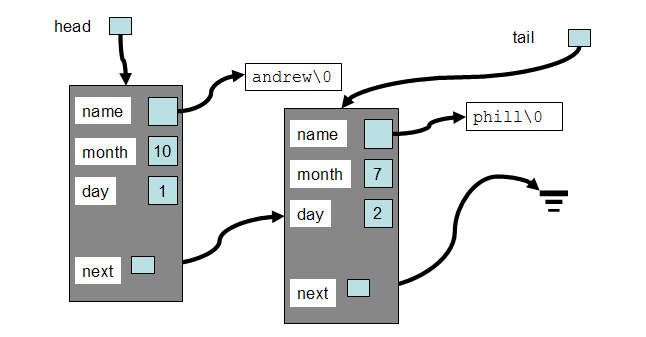
More realistic would be a linked list node like the following, which might be used to keep track of a list of birthdays. Each node contains a pointer to a name (also allocated from space on the heap), and two integers with the month and day of a birthday. In practical applications of linked lists, you will most likely have a linked list node structure that corresponds to whatever problem you are solving.
struct Birthday_S
{
char *name;
int month;
int day;
Birthday_S *next;
};
That would be used to make a list such as this one:
Next time (Monday 4/24): an example of a program that reads from a file and produces a linked list containing all the integers in that file.
![]()
